*알고리즘 이론은 복습 용도로 작성되었습니다. 간략하게 작성되어 있을 수 있으며 해당 알고리즘을 어느정도 알고있다는 전제하에 작성되었습니다.
1. 플로이드 워셜 알고리즘이란?
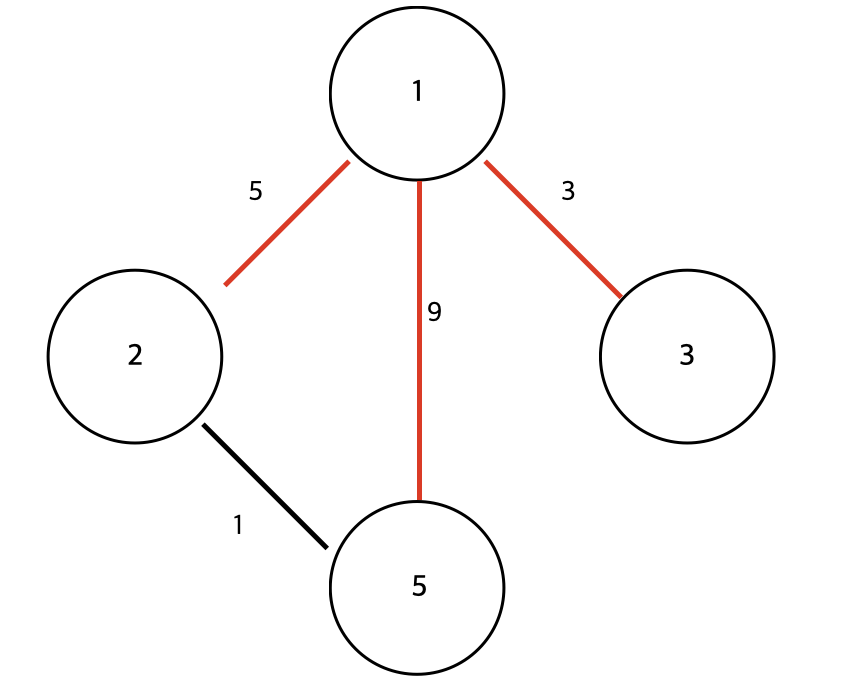
최단 경로 알고리즘 중 하나로, 모든 노드에서 모든 노드까지의 최단 경로를 모두 구하는 알고리즘 입니다.
플로이드 워셜 알고리즘은 거리 정보를 계산할 때, 점화식을 활용한다는 점에서 다이나믹 프로그래밍이 적용되어 있다고 할 수 있습니다.
점화식은 다음과 같습니다.
$$D_{ab} = min(D_{ab}, D_{ak} + D_{kb})$$
동작과정은 다음과 같습니다.

1. 초기 값 입력.
| 0 | 1 | 4 | INF |
| 7 | 0 | 2 | 2 |
| 5 | INF | 0 | 3 |
| 1 | INF | INF | 0 |
각 간선(edge)에 대한 cost가 주어진다고 가정하였을 때, 이차원 배열에 해당 cost를 갱신 시킵니다.
자기 자신에 대한 cost는 0이며, 갈 수 없는 노드는 INF로 초기화 합니다.
2. 각 노드를 순회하며, 해당 노드를 거쳐갈 수 있는 경로 확인 및 갱신
| 0 | 1 | 4 | INF |
| 7 | 0 | 2 | 2 |
| 5 | INF -> 6 | 0 | 3 |
| 1 | INF -> 2 | INF -> 5 | 0 |
예를 들어, 모든 1번 노드에 대해서 거쳐갈 수 있는 경로는 다음과 같습니다.
$$D_{23} = min(D_{23}, \, D_{21}+D_{13}) \qquad =>min(2,7+4) == 2$$
$$D_{24} = min(D_{24}, \, D_{21}+D_{14}) \qquad =>min(2,7+INF) == 2$$
$$D_{32} = min(D_{32}, \, D_{31}+D_{12}) \qquad =>min(INF,5+1) == 6$$
↑update
$$D_{34} = min(D_{34}, \, D_{31}+D_{14}) \qquad =>min(3,5+INF) ==3$$
$$D_{42} = min(D_{42}, \, D_{41}+D_{12}) \qquad =>min(INF,1+1) == 2$$
↑update
$$D_{43} = min(D_{43}, \, D_{41}+D_{13}) \qquad =>min(INF,1+4)==5$$
↑update
이와 같이 거쳐가는 경로를 계산하여, 기존 담겨있는 cost보다 더 낮은 cost가 든다면 table을 갱신하여 줍니다.
이 과정을 모든 노드에 대하여 반복하여 줍니다.
2. 코드구현
코드는 백준 알고리즘 11404번을 기반으로 작성되었습니다.
- 이차원 배열(= 거리 테이블)에 대하여, 자신한테로의 경로를 0으로 초기화 해줍니다.
- 간선와 cost에 대한 정보를 입력받아 거리 테이블에 갱신하여 줍니다.
- 3중 for문을 통해, 각 노드별로 거쳐가는 경로(점화식 기반)를 모두 탐색하고 거리 테이블을 갱신합니다.
import sys
INF = sys.maxsize
n = int(input()) # number of city
m = int(input()) # number of bus
graph = [[INF] * (n+1) for _ in range(n+1)]
for i in range(1, n+1):
for j in range(1, n+1):
if i == j:
graph[i][j] = 0 # path to self = 0
for _ in range(m):
a, b, c = map(int, sys.stdin.readline().split())
graph[a][b] = min(graph[a][b],c) # update array about initial path
# D_ab = D_ak + D_kb
for k in range(1,n+1):
for a in range(1,n+1):
for b in range(1, n+1):
graph[a][b] = min(graph[a][b], graph[a][k] + graph[k][b])
for i in range(1,n+1):
for j in range(1, n+1):
if graph[i][j] == INF:
graph[i][j] = 0
for i in range(1, n+1):
print(*graph[i][1:])
# print(' '.join(map(str,graph[i][1:])))
- Reference
'알고리즘 > 이론' 카테고리의 다른 글
| [Python] 정렬 알고리즘 간단 정리(selection, insertion, merge, quick sort) (0) | 2023.02.14 |
|---|---|
| [python] 다익스트라(dijkstra) 알고리즘 (0) | 2022.09.27 |
| [python] BFS (0) | 2022.09.26 |
| [python] DFS (1) | 2022.09.23 |
| [python] 이진 탐색(Binary Search) (0) | 2022.09.22 |